In today’s enterprise AI landscape, accuracy and explainability are non-negotiable. Retrieval-Augmented Generation (RAG) systems have become essential in customer support, knowledge management, legal search, and investment research. However, as user queries grow more complex and data sources multiply, traditional RAG is often not enough.
Agentic RAG emerges as a solution. By embedding agentic reasoning into the RAG process, we unlock systems that can plan, adapt, validate, and improve their own information workflows.
This blog post is written for technical product managers, data science leads, and AI solution architects looking to build robust, high-accuracy AI assistants or search systems. We will:
- Explain what Agentic RAG is
- Compare it to traditional RAG and other paradigms
- Provide a practical example from the finance sector
- Share tools and evaluation strategies to get you started

2. What Is Agentic RAG?
Agentic RAG is an advanced RAG system that uses LLM-powered agents to perform multi-step reasoning, dynamic querying, and decision-making throughout the retrieval and response process.
Rather than a static query → retrieve → respond pipeline, Agentic RAG enables autonomous LLM agents to:
- Reformulate and decompose user queries
- Plan retrieval strategies
- Use tools like rerankers, summarizers, and validators
- Verify and improve outputs before presenting them
3. Why Is Agentic RAG Needed?
Modern enterprise use cases demand:
- Multi-document synthesis
- Traceable answers grounded in internal data
- Error recovery and fallbacks (e.g., if no good answer is found)
- Explainability for compliance and business trust
Traditional RAG struggles with complex queries, shallow retrieval, and hallucination risk. Agentic RAG introduces logic, feedback loops, and tool use, making it far more robust for production use.
4. Why Agentic RAG and Not Other Multi-Agent Paradigms?
In the fast-evolving ecosystem of LLM-powered systems, multiple agent paradigms have emerged. Each serves a different purpose and comes with its own strengths and trade-offs. However, when it comes to enterprise-grade, retrieval-grounded applications, Agentic RAG stands out as the most suitable and production-ready solution.
Here’s a comparative look:
| Paradigm | Pros | Limitations |
|---|---|---|
| Tool-using Agents | Great for automation tasks | Poor grounding, hard to trace |
| Collaborative Agents | Rich simulations & planning | Complex, research-stage |
| Agentic RAG | Accurate, explainable QA | Slightly more complex than RAG |
Tool-Using Agents (AutoGPT-style)
These agents are designed to autonomously complete high-level goals using chains of tools. For example, AutoGPT can research a topic, draft a report, and email the result.
Pros:
- Flexible and general-purpose
- Useful for task automation
- Can handle sequential decision-making
Limitations:
- No guaranteed factual grounding or source traceability
- Prone to hallucinations
- Hard to control or audit in regulated industries
Use case fit: Good for automation tasks like writing code, booking appointments, or data scraping, not ideal for high-stakes QA.
Collaborative Multi-Agent Systems
These paradigms simulate multi-agent interaction for goal completion, planning, or coordination (e.g., Voyager in Minecraft, negotiation agents in research).
Pros:
- Powerful for emergent behaviors
- Suitable for simulation, game theory, or distributed systems
Limitations:
- Computationally expensive
- Requires sophisticated orchestration
- Lacks real-world deployment maturity
Use case fit: Best for research and experimental environments, not for enterprise QA or knowledge management.
Agentic RAG
Agentic RAG blends the retrieval accuracy of traditional RAG with the reasoning and tool-use capabilities of agents.
Pros:
- Highly traceable, grounded responses
- Multi-step reasoning with error handling
- Modular, extensible with domain-specific tools
Limitations:
- Slightly more complex to build and tune than traditional RAG
- Requires evaluation pipelines and agent coordination
Use case fit: Ideal for finance, healthcare, legal, enterprise support, or any domain requiring explainable, accurate, and context-aware responses.
Bottom Line
Agentic RAG is the sweet spot between simplicity, reasoning power, and factual grounding. It’s currently the most mature, reliable, and deployable agentic pattern for production-grade knowledge applications.
5. Agentic RAG vs. Traditional RAG
| Feature | Traditional RAG | Agentic RAG |
|---|---|---|
| Query Handling | One-shot query | Agent decomposes/adapts queries |
| Tool Use | No | Yes (e.g., reranker, retriever) |
| Reasoning | None | Chain-of-thought, error recovery |
| Multi-step Execution | No | Yes |
| Use Case Fit | Simple QA, summarization | Complex reasoning, legal, finance |
When to use Traditional RAG:
- Simple, high-speed use cases
- Limited internal data or risk tolerance
When to use Agentic RAG:
- Accuracy-critical workflows
- Multi-hop QA or internal document synthesis
6. How Agentic RAG Works:
Agentic RAG transforms the traditional RAG pipeline into a dynamic, intelligent loop that enables reasoning, correction, and control throughout the information retrieval and generation process. Below is an explanation of each component in the Agentic RAG workflow, as illustrated in the diagram.
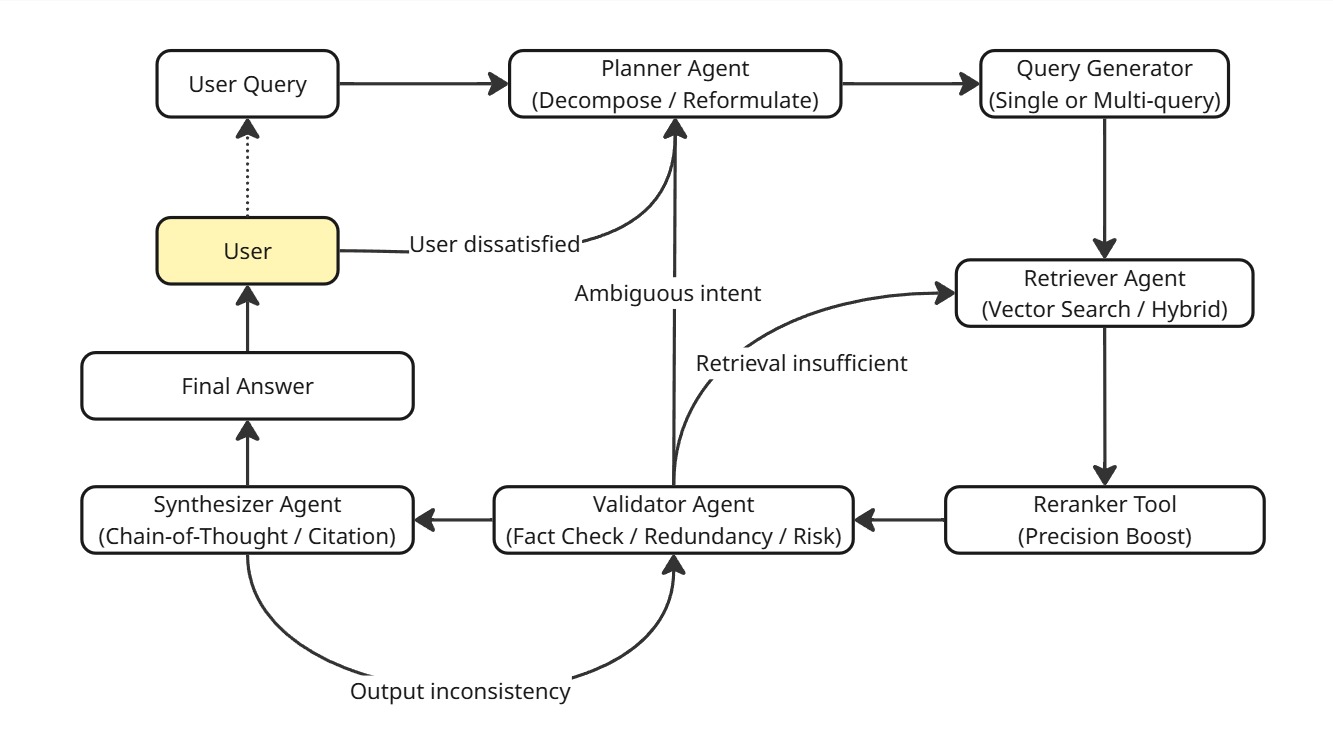
1. User Query
The system begins when the user submits a complex, multi-faceted question. This query often requires decomposition, reasoning, and cross-document synthesis to answer correctly.
2. Planner Agent (Decompose / Reformulate)
The Planner Agent is responsible for:
- Interpreting the query
- Decomposing it into sub-questions if necessary
- Reformulating it for improved clarity or retrieval performance
It also handles routing logic based on ambiguity or failure signals from downstream components.
3. Query Generator (Single or Multi-query)
This module transforms the planner’s structured intent into one or more concrete queries. It may:
- Generate a single semantic search query
- Create multiple sub-queries to broaden coverage (multi-query strategy)
4. Retriever Agent (Vector Search / Hybrid)
The Retriever Agent performs semantic retrieval using a vector database, keyword search engine, or both. It fetches top-k relevant chunks or documents that align with the generated queries.
5. Reranker Tool (Precision Boost)
This tool reorders or filters the retrieval results to improve relevance using more refined models (e.g., BERT-based rerankers or Cohere ReRank). It improves the quality of evidence passed to downstream agents.
6. Validator Agent (Fact Check / Redundancy / Risk)
The Validator Agent ensures that the retrieved content:
- Is factually consistent and relevant
- Addresses all aspects of the original question
- Contains no contradictions or hallucinations
It may call external tools like fact-checkers, structured data lookups, or domain-specific rules. If validation fails, it may:
- Request the retriever to refine the query
- Ask the planner to reframe the task
7. Synthesizer Agent (Chain-of-Thought / Citation)
This agent constructs the final answer using chain-of-thought reasoning, summarization, and citation embedding. It ensures logical coherence, completeness, and proper attribution to sources.
Self-Check Loop: The Synthesizer Agent may detect inconsistencies or missing evidence and send the response back to the Validator Agent for rechecking.
8. Final Answer
Once validated and synthesized, the response is presented to the user with inline citations or supporting metadata.
9. User Feedback Loop
If the user is dissatisfied, their feedback triggers a loop back to the Planner Agent, allowing the system to re-analyze and refine the output process. This loop helps the system improve over time and provide interactive clarification.
Summary of Feedback Loops
- Validator Agent ↔ Planner Agent: Handles ambiguity and initiates task reformulation
- Validator Agent ↔ Retriever Agent: Fetches better evidence if validation fails
- Synthesizer Agent ↔ Validator Agent: Ensures coherence and factual accuracy before finalization
- User ↔ Planner Agent: User feedback re-triggers the planning cycle for clarification or refinement
This architecture enables adaptive, explainable, and high-fidelity AI systems, well-suited for domains like finance, law, and healthcare.
7. Popular Tools for Agentic RAG (Component by Component)
Agentic RAG systems are modular, and each component of the workflow can be powered by different libraries, APIs, or platforms. Here is a breakdown of recommended tools and technologies for each stage of the Agentic RAG pipeline, consistent with the diagram.
Planner Agent (Decompose / Reformulate)
Purpose: Understand the user query and determine whether it needs to be split or reformulated.
Tools:
- OpenAI GPT-4 / Claude 3: Prompted to perform query analysis, reformulation
- LlamaIndex Query Decomposition Module
- LangChain Router Chains: For dynamic route selection
- DSPy Planner (Stanford): LLM-based dynamic planning engine
Query Generator (Single or Multi-query)
Purpose: Translate planner intent into specific queries to maximize recall.
Tools:
- LlamaIndex QueryTransformers: Generate multiple views of the query
- LangChain MultiRetrievalChain: Supports multi-query pipelines
- PromptLayer + OpenAI Functions: For programmatic query generation
Retriever Agent (Vector Search / Hybrid)
Purpose: Retrieve relevant chunks from internal or external knowledge sources.
Tools:
- Chroma / Weaviate / Pinecone / Qdrant: Vector databases
- Elasticsearch / Vespa: For hybrid (keyword + dense) search
- LlamaIndex VectorRetriever
- LangChain Retriever Wrappers
Reranker Tool (Precision Boost)
Purpose: Improve the relevance of retrieved documents using a second-pass ranking.
Tools:
- Cohere ReRank: Out-of-the-box reranker
- BGE-Reranker: Open-source reranker model
- Jina Ranker / ColBERT: Dense reranking tools
- LangChain Rerankers / CrossEncoder
Validator Agent (Fact Check / Redundancy / Risk)
Purpose: Validate factual accuracy, consistency, and completeness.
Tools:
- Retriever-augmented self-consistency prompting
- GPT-4 + custom validators (e.g., Toolformer pattern)
- NeMo Guardrails (NVIDIA): For policy and safety checks
- OpenAI Moderation API: For safety and toxicity filtering
- Guardrails.ai: For prompt & output validation framework
Synthesizer Agent (Chain-of-Thought / Citation)
Purpose: Compose the final answer using structured reasoning and citing sources.
Tools:
- OpenAI GPT-4-turbo / Claude 3: For fluent, cited responses
- LangChain Stuff / MapReduce / Refine chains
- LlamaIndex ResponseSynthesizer: For chunk-based synthesis
- Citation-aware prompting templates
Final Answer + User Feedback
Purpose: Deliver results to the user and optionally support feedback-based loops.
Tools:
- Streamlit / Gradio / React UI: Front-end display layer
- LangChain AgentExecutor + Memory: To manage dialogue state
- Custom feedback logger (e.g., Supabase, AirTable, Firestore)
Summary Table
| Component | Tools / Libraries |
|---|---|
| Planner Agent | GPT-4, Claude 3, LlamaIndex, DSPy, LangChain RouterChains |
| Query Generator | LlamaIndex QueryTransformers, LangChain MultiQuery, PromptLayer |
| Retriever Agent | Chroma, Weaviate, Pinecone, Qdrant, Elasticsearch, LlamaIndex Retriever |
| Reranker Tool | Cohere ReRank, BGE-Reranker, ColBERT, Jina, LangChain Rerankers |
| Validator Agent | NeMo Guardrails, OpenAI Moderation API, Guardrails.ai, GPT-4 Validators |
| Synthesizer Agent | GPT-4, Claude 3, LangChain Chains, LlamaIndex Synthesizer, Custom Templates |
| Final Output + UI | Streamlit, Gradio, LangChain Executor, Custom UIs, Supabase / Firestore |
These tools provide a highly customizable and production-friendly foundation for building scalable Agentic RAG systems.
8. How to Evaluate Agentic RAG Systems
Evaluating Agentic RAG requires going beyond standard RAG benchmarks to assess reasoning ability, agent coordination, and factual robustness. A good evaluation framework should be multi-dimensional, combining retrieval metrics, generation quality, and operational performance.
Below are detailed criteria and practical techniques to assess the performance of Agentic RAG systems:
1. Retrieval Precision\@k
Question: Are we retrieving the most relevant documents or chunks?
Metrics Explained:
- Precision\@k: (number of relevant documents in top K) / K. High precision\@k means the system retrieves mostly useful documents.
- Recall\@k: (number of relevant documents in top K) / (total number of relevant documents in the corpus). Important when multiple answers exist.
- MRR (Mean Reciprocal Rank): The average of the reciprocal ranks of the first relevant result. Helps understand how quickly users find what they need.
- nDCG (normalized Discounted Cumulative Gain): A metric used to evaluate ranking quality in search systems or recommender engines. It measures how well a list of retrieved items is ranked, especially in terms of relevance to the query, while giving more weight to items ranked higher.Accounts for both relevance and position of the correct documents. Higher when relevant items appear near the top.
Tools:
- LlamaIndex / LangChain built-in retrieval eval tools
- Pyserini + BEIR benchmark datasets
How to Test:
- Use labeled QA pairs with known relevant sources
- Compare top-k retrieved chunks to gold documents
2. Factual Accuracy
Question: Does the final answer contain hallucinations or factual errors?
Metrics Explained:
- Human-rated factuality: Human evaluators score answers using Likert scale (e.g., 1-5) or binary correct/incorrect.
- GPT-based factual consistency scoring: Use a second LLM to assess whether the content logically aligns with retrieved evidence.
- RGQA Match Score: Measures whether the response answers the query accurately using the retrieved information.
Tools:
- TruthfulQA, FEVER datasets
- Self-check chains using GPT-4
- NeMo Guardrails or OpenAI Moderation API for rule enforcement
3. Faithfulness to Source
Question: Is the generated answer truly supported by the retrieved content?
Metrics Explained:
- Attribution Rate: Percent of claims in the response that are backed by a cited source.
- Source Overlap Score: Textual overlap between the response and retrieved content.
- Citation Match Rate: Percentage of citations in the answer that point to correct supporting content.
How to Test:
- Run automatic overlap checks between generated answer and retrieved documents
- Use LLM agents to critique alignment between answer and evidence
Tools:
- LlamaIndex faithfulness checkers
- Chain-of-verification prompts in GPT-4
4. Completeness
Question: Does the system fully address all parts of the user’s question?
Approach and Metrics:
- Multi-hop Reasoning Coverage: Ensure the answer includes intermediate reasoning steps across documents.
- Sub-question Resolution Rate: Score answers to decomposed queries and aggregate for completeness.
- Expected Answer Match: Compare against a ground truth multi-part answer (e.g., all sub-questions answered).
Tools:
- Human review with question decomposition templates
- LLM evaluators (e.g., “Did this response fully answer all parts of the user query?”)
5. Latency & Cost
Question: Is the system fast and cost-efficient enough for deployment?
Metrics Explained:
- Response Time per Query (ms): Total time from user input to final answer.
- Number of LLM Calls per Run: Measures compute intensity, especially with multi-agent orchestration.
- Token Usage / Cost per Query: Based on pricing of the LLMs and number of tokens used.
Tools:
- LangChain tracing + OpenAI cost estimation
- PromptLayer / LangFuse dashboards
- Server-side profiling with logs and metrics
Feedback-Driven Evaluation
Integrate live user feedback loops into your system to:
- Collect thumbs-up/down on answers
- Monitor user re-queries as a proxy for dissatisfaction
- Use feedback to fine-tune Planner and Validator agents
Tools:
- Supabase / Firestore for logging
- Streamlit/Gradio components for UI-based feedback
Recommendation
To fully evaluate an Agentic RAG system:
- Use retrieval and generation benchmarks (e.g., HotpotQA, FEVER, TruthfulQA)
- Involve humans in the loop where high stakes are involved
- Track query-level breakdown to analyze which component failed (retriever, planner, synth, etc.)
This level of granular evaluation ensures that your system is not only functional but reliable, explainable, and ready for enterprise deployment.
9. Example: Agentic RAG in Finance
Use Case: Investment Research Assistant
A global investment firm develops an internal AI assistant to help equity analysts rapidly interpret financial performance from earnings call transcripts and company filings. The goal is to answer:
“How did Company X explain the YoY margin change in their Q2 earnings call?”
Glossary:
- YoY (Year-over-Year): Compares one period with the same period from the previous year.
- Margin: Typically refers to profit margin, calculated as a percentage of revenue that remains after subtracting costs.
- Q2 (Quarter 2): Refers to the second quarter of a company’s fiscal year (usually April–June).
This is a complex question that requires:
- Multi-hop reasoning (connecting information across multiple documents)
- Parsing long financial texts (like call transcripts and reports)
- Synthesizing both qualitative (narrative explanation) and quantitative (numerical) data
- Ensuring high factual accuracy for investment decisions
Using Agentic RAG, here’s how the system processes the query step-by-step, aligned with the Agentic RAG architecture:
1. Planner Agent
-
Task: Understands the question and splits it into subcomponents:
- Subquery A: “What was the YoY margin change in Q2?”
- Subquery B: “How did leadership explain the margin change?”
-
Output: Sends structured subquestions and keywords to the Query Generator.
2. Query Generator
- Task: Generates optimized search queries based on subquestions.
-
Example Queries:
- “Q2 margin YoY change site:companyx.com/investor”
- “Company X Q2 earnings call commentary on margin decline”
- Output: Multiple targeted queries are routed to the Retriever Agent.
3. Retriever Agent
-
Task: Pulls relevant information from a database that stores:
- Earnings call transcripts – verbatim discussions between executives and analysts
- SEC 10-Q filings – standardized quarterly financial statements filed with regulators
- Internal research summaries – curated notes or summaries by analysts
-
Output: Text chunks with financial data and leadership commentary.
4. Reranker Tool
-
Task: Improves quality by reordering results to prioritize:
- Sections from transcripts labeled as “Q&A” (where analysts ask questions) or “Outlook” (forward-looking statements)
- Content that includes numeric changes (e.g., revenue drop, margin shifts) and associated explanations
-
Output: Top-ranked excerpts passed to the Validator.
5. Validator Agent
-
Task:
- Checks quoted numbers against official SEC filings (e.g., 10-Q)
- Ensures management’s explanation aligns with the reported margin drop
- Filters out vague or non-specific language (“boilerplate”) and speculative statements
Glossary:
- Boilerplate language: Generic, overused statements that provide little concrete insight (e.g., “We remain committed to excellence”).
- Speculative claims: Statements without factual support, often phrased with uncertainty.
-
Fallback Logic: If validation fails, the agent requests broader context from the retriever.
6. Synthesizer Agent
-
Task:
- Creates a fluent, concise summary
- Embeds citations with timestamps for audio/video transcripts
- Explains how the margin change was justified
-
Output: “Company X reported a 2.3% YoY margin decline in Q2, driven primarily by elevated input costs and lower pricing power in their consumer electronics division. During the Q2 earnings call (28:13 mark), CFO Sarah Kim noted that inventory overhang from Q1 led to discounting pressure, reducing gross margin by approximately 150 basis points (bps).”
Glossary:
- Input costs: The cost of materials or resources used to produce goods.
- Pricing power: A company’s ability to raise prices without losing customers.
- Inventory overhang: Excess stock left over from previous periods.
- Discounting pressure: The need to lower prices to sell excess products.
- Gross margin: Revenue minus cost of goods sold, expressed as a percentage.
- Basis points (bps): 1 basis point = 0.01%. 150 bps = 1.5%.
Final Output
-
Displayed to analysts via a dashboard including:
- Summarized insight with reasoning
- Inline citations linking to source docs and timestamps
- Option to explore supporting evidence with one click
Example Business Impact
- Reduced research time by 70%
- Improved accessibility for non-finance stakeholders (e.g., compliance, ESG)
- Ensured transparency by showing source grounding and reasoning path
Agentic RAG didn’t just answer the question, it explained how the answer was derived, giving stakeholders both speed and confidence.
10. Conclusion
Agentic RAG is the natural evolution of retrieval-based AI systems, combining the precision of RAG with the reasoning and planning capabilities of agents. It is especially powerful in regulated, high-stakes, or information-dense industries like finance, legal, and healthcare.
If you’re building an AI system that needs to think before it speaks, and back up its answers, Agentic RAG is the pattern to adopt.
For further inquiries or collaboration, feel free to contact me at my email.